More-Efficient “Kernel Methods” Dramatically Reduce Training Time for Natural-Language-Understanding Systems
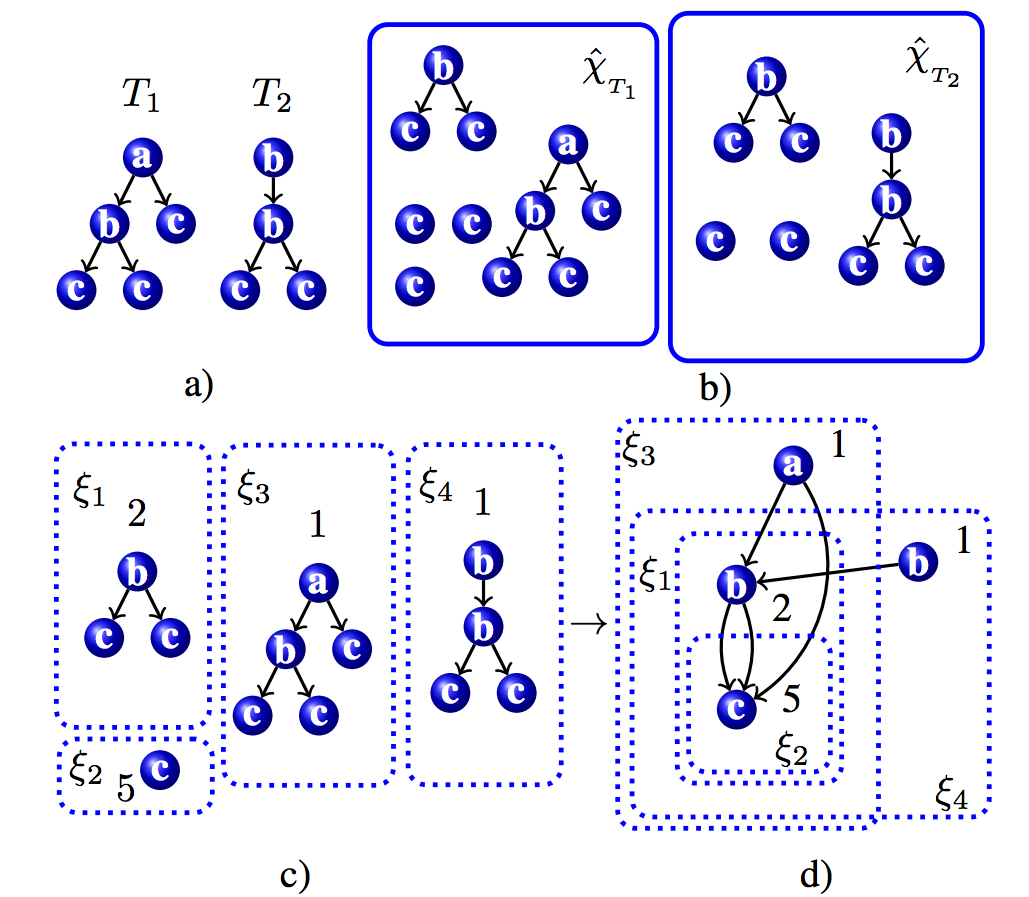
Machine learning systems often act on “features” extracted from input data. In a natural-language-understanding system, for instance, the features might include words’ parts of speech, as assessed by an automatic syntactic parser, or whether a sentence is in the active or passive voice. Some machine learning systems could be improved if, rather than learning from extracted features, they could learn directly from the structure of the data they’re processing.
To determine parts of speech, for instance, a syntactic parser produces a tree of syntactic relationships between parts of a sentence. That tree encodes more information than is contained in simple part-of-speech tags, information that could prove useful to a machine learning system. The problem: comparing data structures is much more time consuming than comparing features, which means that the resulting machine learning systems are frequently too slow to be practical.
In a paper we’re presenting at the 33rd conference of the Association for the Advancement of Artificial Intelligence (AAAI), my colleagues at the University of Padova and the Qatar Computing Research Institute and I present a technique for making the direct comparison of data structures much more efficient. In experiments involving a fundamental natural-language-understanding (NLU) task called semantic-role labeling, with syntactic trees as inputs, we compared our technique to the standard technique for doing machine learning on data structures. With slightly over four hours of training, a machine learning system using our technique achieved higher accuracy than a system trained for 7.5 days with the standard technique.
Source: amazon.com