Kiali with production-scale Prometheus
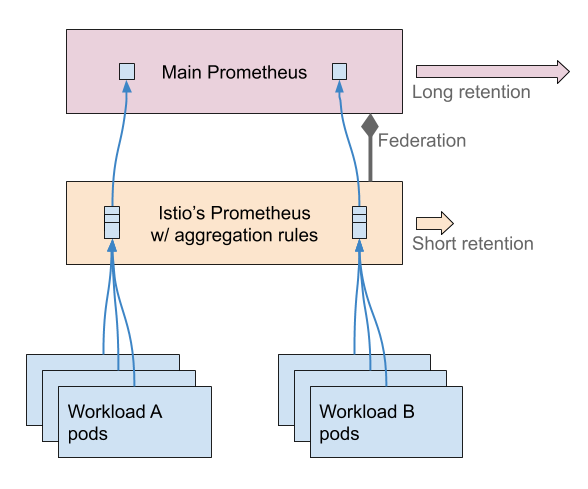
Of course, a definition of “production-scale Prometheus” can be as wide as the variety of cases where Istio and Prometheus are used in production. So in the context of this article, we have to make some assumptions. First of all, this article focuses on Istio using Telemetry v2, which is enabled by default starting from Istio 1.5.
This feature was also present as an experimental feature (disabled by default) in previous releases of Istio. Secondly, this post is written in reaction to the Istio guidelines that were written precisely to describe how to set up Prometheus for production-scale. So you can refer to these guidelines, or also read the article that inspired them, to get the details of that setup.
But let me summarize the key points: Unlike in telemetry v1, envoy sidecars directly report (expose) the Istio metrics to Prometheus, instead of going through Mixer. The main motivation is to remove the bottleneck that Mixer was with respect to the telemetry. But a side effect is that it increases the metrics cardinality because they are now per-pod, not per-workload (Mixer was doing this pods aggregation).
The production-scale setup addresses this issue.
Source: medium.com